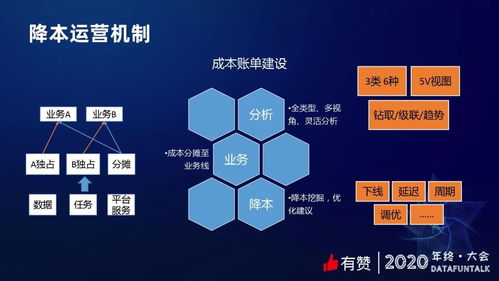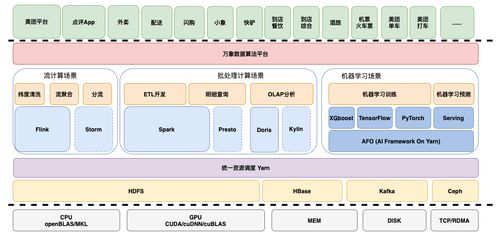
在當今數據驅動的時代,企業面臨著處理海量、多樣、高速生成數據的巨大挑戰。傳統的數據倉庫架構在處理非結構化數據、實時流數據以及支持探索性分析方面日益捉襟見肘。在此背景下,數據湖(Data Lake) 應運而生,并逐漸成為現代數據架構的核心組成部分。它不僅是一種技術架構,更是一種數據管理理念的演進,深刻影響著在線數據處理(OLAP)與在線交易處理(OLTP)業務的融合與創新。
一、數據湖的核心價值
數據湖的核心價值在于其開放性、靈活性與成本效益。
- 存儲所有,無需預定義:數據湖允許企業以原生格式(如文本、圖像、日志、JSON、CSV等)存儲來自任何來源的原始數據,無需在數據攝入前就定義其模式或用途。這打破了傳統ETL過程中“先建模后使用”的束縛,為數據的探索性分析和未來未知的應用場景保留了最大可能性。
- 支持多樣化的分析場景:從傳統的批處理報表、即席查詢,到高級的機器學習、人工智能模型訓練,再到實時的流處理分析,數據湖都能提供統一的存儲底座。分析師、數據科學家和業務用戶可以直接訪問原始數據,使用各自擅長的工具(如SQL、Python、Spark等)進行探索和挖掘。
- 性價比與可擴展性:通常構建在低成本的對象存儲(如AWS S3、Azure Blob Storage)之上,數據湖能夠以極具競爭力的成本存儲PB甚至EB級別的數據。其存儲與計算分離的架構,使得計算資源可以按需彈性伸縮,有效控制成本。
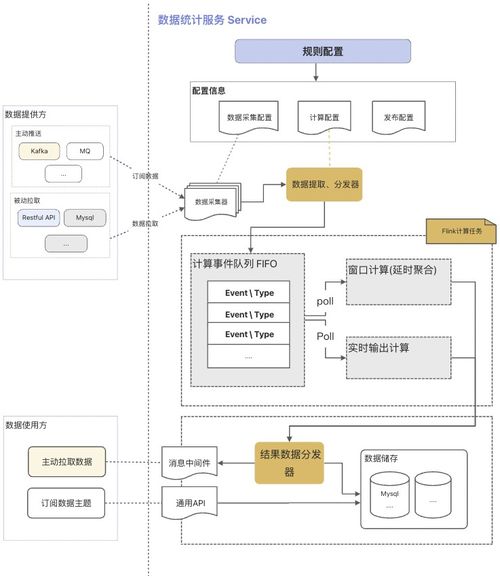
二、數據湖的典型架構
一個成熟的數據湖架構通常包含以下幾個層次:
- 存儲層:是整個架構的基石,基于可擴展的對象存儲服務。數據以原始格式按需分區存儲,并輔以元數據管理(如數據目錄、數據血統、數據質量信息),實現數據的“可發現”與“可理解”。
- 攝入與處理層:負責將數據從各種源頭(數據庫、IoT設備、應用程序日志、第三方API等)以批處理或流處理的方式引入湖中。處理層則負責數據的清洗、轉換、標準化和聚合,可能使用Spark、Flink、Hive等計算框架。這里常引入“Medallion”架構(青銅/原始層、白銀/清洗層、黃金/應用層) 來組織數據,確保數據質量逐層提升。
- 服務與消費層:為上層應用提供數據服務接口。這包括:
- SQL查詢引擎(如Presto/Trino, Athena, Spark SQL)用于交互式分析。
- 機器學習平臺提供特征存儲和模型訓練環境。
- 數據API或數據服務層,將處理好的數據以結構化方式(如表格式,如Iceberg、Hudi、Delta Lake)暴露給下游的OLAP系統或直接服務于應用程序。
- 治理與安全層:貫穿始終,包括數據血緣追蹤、數據質量管理、訪問權限控制、數據加密和合規性審計。這是保障數據湖從“數據沼澤”變為“數據綠洲”的關鍵。
三、數據湖與在線數據處理(OLAP)及交易處理(OLTP)的協同
數據湖并非要取代傳統的OLAP(數據倉庫)和OLTP(業務數據庫)系統,而是與它們構成一個互補協同的現代數據棧。
* 賦能OLAP:從敏捷分析到統一數據底座
傳統數據倉庫是高度結構化、面向主題的,適合穩定的報表和BI分析。數據湖則作為其上游的“數據補給站”和“創新沙盒”。原始數據先入湖,經過探索、清洗和初步加工后,將高質量、高價值的“黃金”數據集以優化的格式(如列存表)同步或物化到數據倉庫中,供高性能BI查詢。數據湖自身也能通過高性能查詢引擎直接支持靈活的、探索式的OLAP查詢,兩者形成“湖倉一體”的架構。
* 連接OLTP:從數據孤島到實時洞察
OLTP系統(如關系型數據庫)專注于高并發、低延遲的事務處理,其產生的業務數據(如訂單、用戶行為日志)是數據湖最重要的數據源之一。通過變更數據捕獲(CDC)技術,可以將OLTP數據庫的實時增量變化近乎實時地流入數據湖。這使得:
- 業務狀態得以實時鏡像:在湖中構建一個與生產數據庫幾乎同步的副本,用于分析查詢,避免對生產庫造成壓力。
- 支持實時分析:流處理引擎可以直接處理流入數據湖的實時數據流,實現實時監控、實時預警和實時個性化推薦等場景。
- 反饋與優化:在數據湖中通過分析挖掘得出的洞察(如用戶偏好模型、風險預測模型),可以通過API或微服務的形式,低延遲地反饋回OLTP業務系統,優化業務流程,實現數據驅動的閉環。
###
數據湖的價值遠不止于一個低成本的海量存儲池。它以原始數據為中心、存儲計算分離的架構,為企業提供了應對數據多樣性和需求不確定性的終極靈活性。通過合理的架構設計與嚴格的數據治理,數據湖能夠有效融合OLTP系統的實時業務數據與OLAP系統的深度分析能力,成為企業數字化轉型的中央數據樞紐。隨著湖倉一體架構的成熟和數據網格等分布式數據管理理念的普及,數據湖將在解鎖數據價值、驅動業務創新的道路上扮演更加核心的角色。